Power Plant ML Pipeline
Period: 04/2022
Project Name: Power Plant ML Pipeline
Machine Learning Python Spark SQL PySpark
What's the Project For?
- Assignment for the course 'Cloud Computing and Big Data Systems' for the degrees in HKUST.
Business Problem:
The challenge for a power grid operator is how to handle a short fall in available resources versus actual demand. One solution to it is to turn on small Peaker or Peaking Power Plants which is of high cost per kilowatt hour, and another is to buy expensive power from another grid. In order to make better economic trade-offs about the number of peaker plants to turn on or whether to buy from another grid, the grid operator would like to know an estimation of the power output of a peaker power plant (while this would depends on the environmental conditions).
Task (Supervised Regression Problem):
Predict power output given a set of environmental readings from various sensors (i.e., Atmospheric Temperature in C, Exhaust Vacuum Speed, Atmospheric Pressure, and Relative Humidity) in a natural gas-fired power generation plant.
Dataset
- 9568 data points collected over 6 years
- 4 environmental attributes: AT, V, AP, RH
- UCI Machine Learning Repository Combined Cycle Power Plant Data Set
- Label/Target: PE (numeric)
Project Pipeline
1. Extract-Transform-Load (ETL) the data
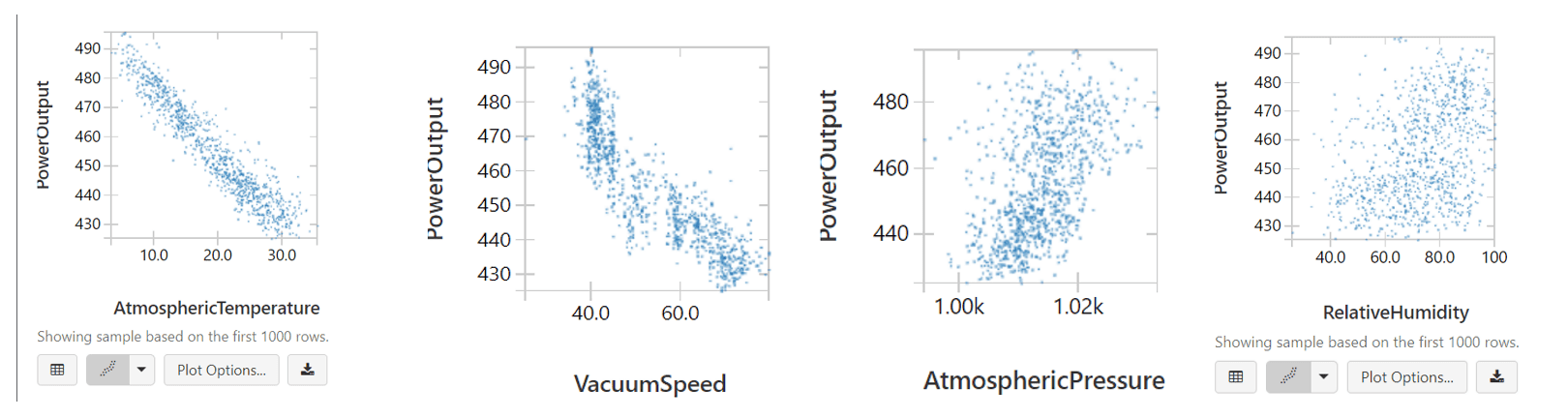
2. Explorative Data Analysis
- Using Spark SqL and visualization in Databricks to draw the scatter plot for different features with the label
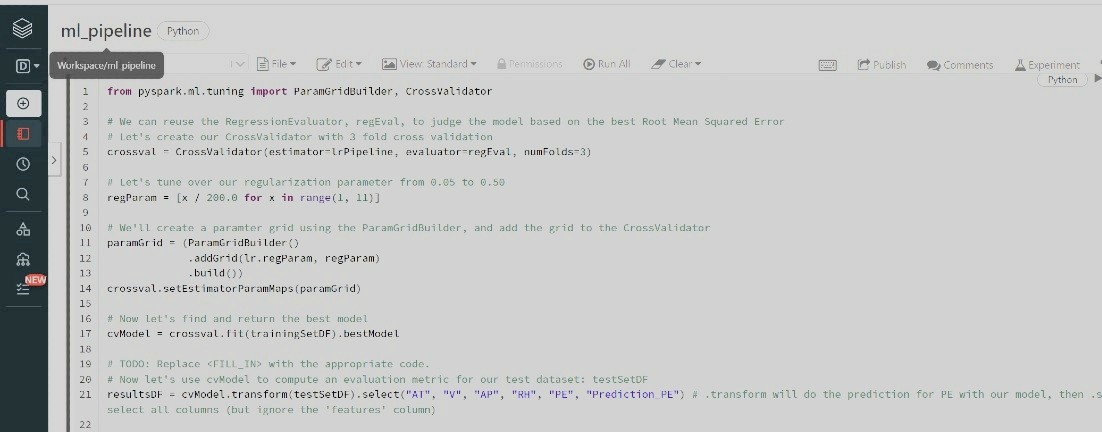
3. Data Preparation
- Build ML pipeline to convert the predictor features from DataFrame columns to Feature Vectors
- Split into training and test dataset
4. Model Training & Tuning
- Building pipeline: 1) convert to feature vector 2) linear regression OR decision tree regression OR random forest tree
- Create a CrossValidator to perform k-fold validation on different hyperparameters values
5. Model Evaluation
- Computing the Coefficient of Determination (R^2) and Root Mean Square Error (RMSE)
Project Result
The best model in this assignment was the Random Forest Tree Model using an ensemble of 25 trees with a depth of 8.
Most Challenging Part of the Project?
The most challenging part in this assignment was to understand the key concepts since some of the terms used in the assignment was not taught during class, and some of them were not appeared in machine learning in a non-cloud environment.
For example, I have to read through the documentation to understand the concept of Transformer, which is an algorithm that transform a DataFrame into another DataFrame (i.e. a ML model), or an Estimator, which is an algorithm that can be fit on a DataFrame to produce a Transformer (i.e., learning algorithm that trains on DataFrame to produces a model).
On the other hand, learning the API for spark like ParamMap and VectorAssembler was also a bit challenging and fun XD